Kafka là gì? Đây là câu hỏi mà nhiều nhà phát triển đặt ra khi tiếp xúc với các hệ thống phân tán và xử lý dữ liệu thời gian thực. Trong bài viết này, chúng ta sẽ khám phá định nghĩa, cấu trúc, tính năng, ứng dụng thực tế và lợi ích mà Kafka mang lại cho các developer.
Giới thiệu tổng quan về Apache Kafka
Apache Kafka là một nền tảng truyền dữ liệu (streaming platform) mã nguồn mở, được thiết kế để xử lý các luồng dữ liệu thời gian thực với tốc độ cao. Nó hoạt động theo mô hình publish-subscribe, cho phép các ứng dụng (producers) gửi dữ liệu vào các kênh (topics) và các ứng dụng khác (consumers) nhận và xử lý dữ liệu này. Có thể hình dung Kafka như một “trung tâm trung chuyển dữ liệu” giúp các hệ thống phức tạp giao tiếp và chia sẻ thông tin một cách hiệu quả.
Kafka là gì?
Kafka là một hệ thống phân tán, có khả năng mở rộng và chịu lỗi cao. Nó thường được sử dụng để xây dựng các hệ thống luồng dữ liệu thời gian thực (real-time data pipelines) và các ứng dụng truyền dữ liệu (streaming applications).

Kafka là một hệ thống phân tán, có khả năng mở rộng và chịu lỗi cao
Nguồn gốc và sự phát triển
Kafka được phát triển ban đầu bởi LinkedIn vào năm 2010, với mục tiêu giải quyết vấn đề xử lý log nội bộ hiệu quả hơn. Năm 2011, LinkedIn đã trao tặng Kafka cho cộng đồng mã nguồn mở và hiện tại, nó được duy trì và phát triển bởi Apache Software Foundation. Sự ra đời của Kafka nhằm thay thế các cơ chế xử lý log phức tạp và cồng kềnh, mang lại một giải pháp pub-sub mạnh mẽ và hiệu quả hơn.
Kafka dùng trong trường hợp nào?
Kafka được sử dụng rộng rãi trong nhiều ứng dụng khác nhau, bao gồm:
- Hệ thống xử lý dữ liệu thời gian thực yêu cầu tốc độ cao và độ trễ thấp.
- Các nền tảng kiến trúc microservices cần một hệ thống trung chuyển dữ liệu đáng tin cậy.
- Ứng dụng thương mại điện tử (theo dõi hành vi người dùng, xử lý giao dịch).
- Ứng dụng tài chính (phát hiện gian lận, giao dịch chứng khoán).
- Ứng dụng IoT (thu thập dữ liệu từ các thiết bị cảm biến).
- Hệ thống log (thu thập và phân tích log từ nhiều nguồn).
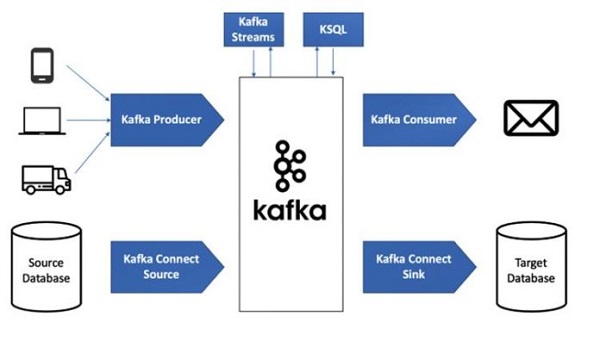
Cấu trúc và cách thức hoạt động của Kafka
Để hiểu rõ hơn về Kafka, chúng ta cần đi sâu vào cấu trúc và cách thức hoạt động của nó.
Kafka là một hệ thống phân tán, có khả năng mở rộng và chịu lỗi cao
Mô hình hoạt động publish–subscribe
Mô hình publish-subscribe là nền tảng của Kafka. Producers (người sản xuất) gửi dữ liệu (message) tới các Topics. Consumers (người tiêu dùng) đăng ký (subscribe) vào các Topics để nhận dữ liệu. Ưu điểm của mô hình này:
- Giảm độ phụ thuộc giữa các hệ thống: Producers và Consumers không cần biết đến sự tồn tại của nhau.
- Dễ scale và bảo trì: Các thành phần có thể được thêm hoặc gỡ bỏ mà không ảnh hưởng đến hệ thống.
- Hạn chế latency: Xử lý dữ liệu bất đồng bộ giúp giảm độ trễ.
Thành phần cơ bản trong kiến trúc Kafka
Kiến trúc của Kafka bao gồm nhiều thành phần phối hợp với nhau:
- Producers: Tạo và gửi dữ liệu (event) vào các topics.
- Consumers: Đọc và xử lý dữ liệu từ các topics.
- Topics: Các kênh logic để phân loại và phân phối dữ liệu.
- Partitions: Các phần nhỏ hơn của topic, giúp tăng khả năng mở rộng và song song. Mỗi partition được lưu trữ trên một broker.
- Brokers: Các server lưu trữ các topics và partitions.
- Cluster: Tập hợp các brokers, tạo thành một hệ thống Kafka hoàn chỉnh.
- Zookeeper/KRaft: Hệ thống quản lý metadata (thông tin về cluster, topics, partitions, v.v.). Kafka 2.8 trở đi hỗ trợ KRaft mode, thay thế Zookeeper để đơn giản hóa việc quản lý.
Lưu trữ và đảm bảo thứ tự sự kiện
Kafka không chỉ truyền dữ liệu, mà còn lưu trữ chúng theo thời gian. Mỗi message được gán một offset, cho biết vị trí của message trong partition. Điều này đảm bảo rằng:
- Dữ liệu được lưu trữ bền vững.
- Thứ tự của các message được bảo toàn trong mỗi partition.
- Consumers có thể đọc lại dữ liệu từ bất kỳ offset nào.
Nhờ đó, Kafka rất phù hợp cho các ứng dụng cần xử lý dữ liệu theo thứ tự, theo thời gian thực và có khả năng replay lại các sự kiện đã xảy ra.
Những tính năng nổi bật của Apache Kafka
Kafka nổi bật nhờ những tính năng vượt trội, khiến nó trở thành lựa chọn hàng đầu cho các hệ thống streaming dữ liệu.
Những tính năng nổi bật của Apache Kafka
Xử lý dữ liệu với hiệu suất cao
Kafka có khả năng xử lý hàng triệu message mỗi giây, nhờ vào:
- Kiến trúc chia partition, cho phép xử lý song song.
- Khả năng scale broker một cách dễ dàng, tăng throughput tuyến tính.
- Thiết kế tối ưu cho việc đọc/ghi tuần tự trên disk.
Điều này khiến Kafka trở thành lựa chọn lý tưởng cho các hệ thống Big Data và Data Ingestion ở quy mô lớn.
Tính bền vững và an toàn dữ liệu
Kafka đảm bảo an toàn dữ liệu bằng cách:
- Hỗ trợ replication (sao chép) dữ liệu giữa các broker.
- Đảm bảo dữ liệu không bị mất khi một broker gặp sự cố.
- Sử dụng log compaction để chỉ giữ lại sự kiện mới nhất cho mỗi key, giúp tiết kiệm dung lượng lưu trữ.
- Cho phép thiết lập thời gian retention (thời gian lưu trữ) cho các message.
Độ trễ thấp và khả năng xử lý thời gian thực
Kafka mang lại khả năng xử lý dữ liệu gần như thời gian thực với độ trễ thấp, phù hợp cho các ứng dụng như:
- Phát hiện gian lận (fraud detection).
- Theo dõi hành vi người dùng.
- Thu thập dữ liệu telemetry.
Tích hợp mạnh mẽ với hệ sinh thái khác
Kafka dễ dàng tích hợp với các công nghệ khác, tạo nên một hệ sinh thái mạnh mẽ:
- Spark, Hadoop: Phân tích Big Data.
- Flink: Xử lý stream.
- Elasticsearch: Truy vấn log.
- Redis, MongoDB: Ứng dụng NoSQL/Caching.
- Kafka Connect: Kết nối dễ dàng với các data sources/sinks (ví dụ: database, cloud storage).
Ứng dụng Kafka trong thực tế
Kafka được ứng dụng rộng rãi trong nhiều lĩnh vực khác nhau.

Ứng dụng Kafka trong thực tế
Trong phát triển phần mềm và DevOps
- Thu thập log tập trung (centralized logging).
- Truyền dữ liệu giữa các microservices một cách bất đồng bộ.
- Giao tiếp event-driven giúp tăng tính linh hoạt và khả năng scale cho hệ thống.
Trong thương mại điện tử & tài chính
- Xử lý giao dịch trực tuyến (online transaction) thời gian thực.
- Phát hiện gian lận ngay lập tức (instant fraud detection).
- Đệm xử lý order và thanh toán khi hệ thống backend tạm thời gián đoạn.
Trong phân tích dữ liệu nâng cao
- Kafka đóng vai trò là “ống dẫn dữ liệu” (data pipeline).
- Ingest dữ liệu vào kho dữ liệu (Hadoop, Druid, v.v.).
- Stream analytics để phân tích hành vi khách hàng thời gian thực.
Trong IoT và công nghiệp
- Cảm biến truyền dữ liệu bất đồng bộ qua Kafka.
- Ứng dụng trong predictive maintenance (dự đoán hỏng hóc dựa trên AI/ML).
- Sử dụng rộng rãi trong các doanh nghiệp sản xuất/logistics quy mô lớn.
Lợi ích của Kafka đối với Developer

Kafka mang lại nhiều lợi ích cho developer
Tăng hiệu quả hệ thống và hiệu suất ứng dụng
- Kafka giúp tách biệt (decouple) xử lý và giao tiếp giữa các services.
- Cải thiện hiệu suất và giảm bottleneck nhờ xử lý bất đồng bộ.
- Developer dễ dàng triển khai kiến trúc Event-Driven / Microservice.
Đơn giản hóa việc xử lý dữ liệu phân tán
- Kafka cho phép xây dựng data pipeline một cách dễ dàng.
- Giảm độ phụ thuộc giữa các thành phần (loosely coupled system).
- Có thể tận dụng lại dữ liệu bằng cách replay các event, xử lý lại nhiều lần.
Học nhanh, setup dễ và giàu tài liệu chính thống
- Kafka có hỗ trợ phong phú cho nhiều ngôn ngữ: Java, Python, Node.js, Scala, v.v.
- Tài liệu đầy đủ từ cộng đồng lớn (Apache, Confluent).
- Nhiều công cụ UI/CLI và local cluster setup, ít yêu cầu cấu hình.
Khi nào nên (và không nên) chọn Kafka?
Để đưa ra quyết định phù hợp, hãy xem xét các trường hợp nên và không nên sử dụng Kafka.
Trường hợp nên dùng Kafka
- Khi yêu cầu xử lý sự kiện thời gian thực với throughput lớn.
- Khi cần scale và chia hệ thống phức tạp thành các module nhỏ.
- Khi muốn xây dựng Event Sourcing / CQRS.
Trường hợp không nên chọn Kafka
- Dự án quá nhỏ, không đủ nguồn lực để vận hành hệ thống phức tạp như Kafka.
- Muốn một hệ thống message queue đơn giản, ít cấu hình (ví dụ: Redis pub/sub, RabbitMQ).
- Ứng dụng không yêu cầu truyền dữ liệu dạng stream real-time.
Những cập nhật quan trọng và xu hướng tương lai

Kafka liên tục phát triển với những cập nhật và xu hướng mới.
Kafka và KRaft: Tương lai không cần ZooKeeper
- Kafka 2.8 giới thiệu Kraft mode, thay thế Zookeeper bằng Raft-metadata hệ thống riêng.
- Ưu điểm:
- Đơn giản hóa vận hành.
- Tự động hóa tốt hơn.
- Tối ưu node tracking & high availability.
Kafka đi cùng cloud & serverless
- Kafka đang được cung cấp dưới dạng dịch vụ (Kafka-as-a-Service) từ Confluent Cloud, AWS MSK, Azure Event Hub.
- Giúp startup và SME dễ dàng tiếp cận Kafka mà không cần tự vận hành.
- Cloud-native Kafka giúp tích hợp nhanh và giảm chi phí hạ tầng ban đầu.
Hệ sinh thái mở rộng: Kafka Streams và Kafka Connect
- Kafka Streams: Viết logic xử lý stream trực tiếp trên Kafka bằng Java/Scala.
- Kafka Connect: Công cụ cho việc kết nối (ETL Streaming gần như no-code).
- Mở rộng luồng dữ liệu nhanh chóng giữa Kafka và các hệ thống nguồn khác.
Kết luận
Hy vọng bài viết này đã cung cấp cho bạn cái nhìn toàn diện về Kafka là gì, cũng như những tính năng, lợi ích và ứng dụng của nó. Kafka là một công cụ mạnh mẽ cho việc xây dựng các hệ thống xử lý dữ liệu thời gian thực, tuy nhiên, việc lựa chọn Kafka hay không phụ thuộc vào yêu cầu cụ thể của dự án.